Hello dear readers,
In today’s article I will show you how to create your Linux DHCP server. DHCP or Dynamic Host Control Protocol is a service which provides IP addressing to your network devices. The difference between assigning static IPs and using a DHCP server is that the IP assignment is made without the interference of System Administrators. Using such service you also have a centralized administration point to your whole infrastructure offering an easy way to assign/change or remove an IP address from your hosts. Every network parameter can be automatically configured by the DHCP server: IP address, network mask, gateway, DNS servers, WINS server address, etc. This service works using the client-server model: the server sends messages using 67 (source) and 68 (destination) UDP port numbers while the client uses port 68 as source and port 67 as destination.
One of the main principles behind this technology is the use of “leased” addresses. This means that each client will be able to use a certain IP address only in the allotted time. Once an IP address has been assigned to a DHCP client, a lease-time duration is set. The client will contact the DHCP server periodically to “renew” it’s IP address. If for whatever reason, the DHCP server does not respond in time, the client will try to contact other DHCP servers by broadcasting a message throughout the network.
Before an IP is assigned to a workstation, several messages are exchanged between the DHCP client and the server. The following picture displays a typical DHCP process:

DHCP Client-Server model
We’ve talked previously about DHCP in
this article when we’ve talked about Windows Server. From above, the whole DHCP IP assignment method looks something like this:
1. client sends a DISCOVER message in which he tries to contact any DHCP server available on the network. This is a broadcast message that uses the UDP port 67 as destination. Unless there is DHCP-Relay configured on the network, this message will be blocked from any edge device (a router). This message can contain an IP address, the last used IP address and/or the lease time.
2. server will respond with an OFFER message that contains all the network parameters. This is also a broadcast message that uses the UDP port 68 as destination.
3. when the client chooses a certain IP configuration, it will send a REQUEST message to the DHCP server to inform that the specified IP address has been chosen. This message is received by all DHCP servers and thus, all will know that the client has received its reservation.
4. server will respond with an ACK (Acknowledge) message and the network parameters will be sent to the client.
Other types of DHCP messages that can be exchanged between the client and the server are:
Decline – the client will refuse to accept the IP allocation because this network address is used by another workstation
NACK – this type of message is sent when the server refuses to lease an IP address
Inform – when certain network parameters must be changed, the client will send an inform message to the server
Release – the client will inform the server that he doesn’t need the reservation anymore
BASIC NETWORK SETUP
For this example, I will install the DHCP server on a CentOS machine, you can choose whatever distribution you like because the config is similar. You’ll need an active Internet connection if you choose to install the DHCP service using the yum tool. To install this service from sources the story is a bit complicated and I will not talk about it right now.
To configure the network parameters, use ifconfig or ip commands:
ifconfig eth0 10.10.10.50 network 255.255.255.0
ip address add 10.10.10.50/24 dev eth0

How to configure Linux IP address
If you need to remove an IP address type ip address del 10.10.10.50/24 dev eth0 or ifconfig eth0 delete 10.10.10.50.
The default route/gateway address can be configured by typing:
route add default gw 10.10.10.1 or ip route add default via 10.10.10.1

How to configure gateway IP in Linux
Once the network parameters have been set, we’ll need to enable the network interface by typing ifconfig eth0 up

How to enable network interface in Linux
To disable a network interface, type ifconfig eth 0 down
We’ll need to add the DNS servers used by our DHCP server. Navigate to /etc/resolv.conf and edit the file using your favorite editor. Once you’ve opened the file, type in the following:
nameserver DNS_SERVER_IP_ADDRESS
Add one entry per line for each DNS server’s IP address

How to configure local DNS servers in Linux
SERVER CONFIGURATION
Now you should be able to ping any website and we are ready to install the DHCP service. There are several things that you’ll need to know before we can proceed with the installation:
- the DHCP service is called dhcpd (DHCP Daemon) and once we’ve configured it, we’ll see this process running on the server.
- In CentOS, the DHCP config file in stored under /etc/dhcp/dhcpd.conf. We’ll need to modify this file to successfully configure our server. Note that if the installation is made from sources, this file will have to be created manually:

DHCP configuration file
As you can see from the output, in CentOS, the configuration file is empty so we need to enter all configuration parameters manually. An example can be seen in /usr/share/doc/dhcp*/dhcpd.conf.sample. Once the configuration is finished, we can validate it using the dhcpd -t command.
To install the DHCP service, type yum install dhcp and wait for the installation to finish. If you don’t know weather your server has this service installed or not, try to install it and you’ll receive the following message:

How to install DHCP in Linux
After the installation has been successfully completed, it’s time to configure our DHCP server by editing the configuration file. Simply copy the content from /usr/share/doc/dhcp*/dhcpd.conf.sample to /etc/dhcp/dhcpd.conf. To achieve this result, type in cat /usr/share/doc/dhcp*/dhcpd.conf.sample > /etc/dhcp/dhcpd.conf
Now open the dhcpd.conf file using your favorite editor. I’ve edited the file and kept only the information that we require for this config. The file should look similar to:
authoritative;
ddns-update-style none;
option domain-name “ppscu.com”;
option domain-name-servers 10.10.10.1; 127.0.0.1
option routers 10.10.10.1
default-lease-time 600;
max-lease-time 7200;
subnet 10.10.10.0 netmask 255.255.255.0 {
range 10.10.10.150 10.10.10.200;
}
Note that the bold lines are the ones that must appear in the config. The # sign is used to comment lines so whatever is written after this character is not executed. It’s important to put the ; character at the end of each line.
I will try to explain each parameter used in our configuration file:
- authoritative – an authoritative server will respond to requests coming from clients that are part of the same subnet. Simply put, if a client from a subnet that was not configured on the DHCP server requests a renew, the DHCP server will send DHCP NACK messages forcing the client to release its IP configuration.
- ddns-update-style none – disables dynamic DNS
- option domain-name “ppscu.com” – sets the domain name of the DHCP clients
- option domain-name-servers 10.10.10.1 – sets the DNS servers used by clients
- option routers 10.10.10.1 – sets the network routers
- default-lease-time 600; and max-lease-time 7200; – the number of seconds a client can hold its IP allocation before submitting a renew
Note that if we include these settings in the subnet config, the settings will only be applied to that particular subnet. In this example we’ve configured the settings for the whole server thus all subnets configured on this machine will carry the same config.
- subnet 10.10.10.0 netmask 255.255.255.0 – the subnet of the DHCP server
- range 10.10.10.150 10.10.10.200; – the pool of IP addresses used by DHCP clients
After we’ve finished our configuration, it’s time to test the config file for errors by typing dhcpd -t. If there are no errors received, the dhcp daemon can be started. You can verify it’s status by typing service –status-all | grep dhcpd

Get DHCP service status
Start the DHCP daemon by typing /sbin/service dhcpd start .You can stop it by typing: /sbin/service dhcpd stop
If you type ps -el | grep dhcpd, you should be able to see the daemon running on your server. If you have any problems with the server at this point, type service dhcpd restart to restart the DHCP daemon:

How to restart DHCP daemon
We can also check if the server
listens on UDP port 67 by typing
netstat -paun

how to verify DHCP port in Linux
p = display PID/Program name for sockets ; a – all ; u – show only UDP ports ; n – numeric
CLIENT CONFIGURATION
On the client side, you will need to type dhclient [interface name] to instruct the DHCP client to listen on the specified interface. After this step is complete, if you type ifconfig or ip addr show, you should be able to see the leased IP address:

how to display IP address in Linux
The dhclient config file is stored in /etc/dhcp/dhclient.conf. By editing this file, we can set custom settings for the DHCP client:

How to configure DHCP client
The database of the DHCP client is stored under /var/lib/dhcp/dhclient.leases
If we return on the server, we can check out the DHCP database in which leased IP addresses are stored. In CentOS, the database can be found in /var/lib/dhcpd/dhcpd.leases and looks something similar to:

DHCP database
This way we can verify what IP addresses have been leased to DHCP clients. The number of leased IP addresses can be easily viewed by typing
dhcpd once the daemon has been started:

Verify DHCP leased IP addresses
If we want to reserve a specific IP for a DHCP client, we’ll need to type in the following (I’ll add comments on each line):
host ubuntu1 { host identification within the dhcpd.conf file
hardware ethernet 00:0c:29:bd:5b:69; – MAC address of the host
option domain-name-servers 10.10.10.1; – specific DNS servers used by this host (optional)
option routers 10.10.10.1; – specific gateway used by the host (optional)
fixed-address 10.10.10.160; – host’s reserved IP address
}
Once you’ve made this configuration, restart the dhcp daemon. On the client side, we will need to disable/enable the network interface by typing ifconfig eth0 down followed by ifconfig eth0 up.
Another method of renewing the leased IP address is by typing: sudo dhclient -r eth0 followed by sudo dhclient eth0
If there are no problems on the server, the DHCP client will renew it’s IP address:

DHCP client renew
We can further modify our dhcpd.config file to set custom settings for a group of DHCP clients by typing:
group {
option domain-name-servers 10.10.10.1; -global settings applied to this groups of hosts
option routers 10.10.10.1;
host ubuntu1 { 00:0c:29:bd:5b:69; } –each DHCP client with it’s corresponding MAC address
host ubuntu2 { 00:0c:29:bd:5b:70; }
host ubuntu3 { 00:0c:29:bd:5b:71; }
}
I’ve tried to cover all main steps that you need to take in order to install and configure DHCP on your infrastructure. We’ve seen how to deploy the DHCP server and configure a client to obtain its IP automatically. Hope I’ve managed to explain all the important steps and you now have a clear understanding of the DHCP protocol how its implemented in Linux distributions. If you have any questions don’t hesitate to post a comment and I’ll respond asap. Wish you all the best!










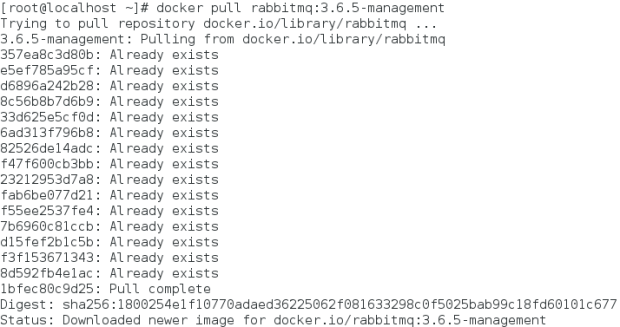
 You can now open a browser and check the rabbitmq management interface on the specified port:
You can now open a browser and check the rabbitmq management interface on the specified port:











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}